Antes de seguir adelante, necesitamos aclarar qué les pasa a los objetos que creamos en una aplicación. Cuándo se crean, dónde se almacenan y cómo se destruyen. En definitiva, necesitamos conocer mejor la vida de los objetos.
El término de variable que usamos en programación tiene su origen en el Álgebra Matemática. Una variable representa cada uno de los grados de libertad que tenemos, de forma que cambiando su valor obtendríamos diferentes resultados de una expresión.
Los primeros lenguajes imperativos, sobre todo BASIC, definieron las variables como espacios de memoria donde almacenar los distintos valores que necesitaba la CPU en sus operaciones. Cada variable se marcaba con un nombre único y se le asignaba un espacio en memoria. Con el fin de reducir el consumo de memoria, estas variables eran reutilizadas una y otra vez a lo largo del programa.
Con los lenguajes procedurales y lenguajes orientados a objetos se cambió este concepto. Los nombres de variables ya no eran únicos. Dos variables podían tener el mismo nombre en distintos ámbitos (scopes), así como dos variables podían representar el mismo dato. El nombre de la variable dejó de representar el espacio físico en memoria para convertirse en un alias con el que nombrar a la variable. El proceso de enlazar un nombre con un valor se llamó binding (enlace) y se hizo fundamental para el funcionamiento de las clausuras.
Se puede definir una variable como la “unión de un nombre y un valor a través de un enlace”.
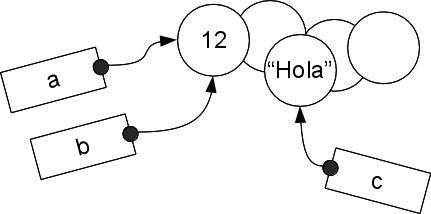
Con este punto de vista, cuando hablamos de “modificar” una variable tenemos dos modos de hacerlo:
- Modificando el valor al que apunta
- Modificando el enlace para apunte a otro valor
Nosotros no sabemos, en realidad, cómo se modifican las variables. Lo único que nos tiene que importar es que nuestra variable modificada apuntará al nuevo valor. Así pues, cuando tenemos un código:
x = 12
y = x
Seguimos diciendo que “a la variable X le asignamos el valor entero 12”, pero lo correcto sería decir que “al entero 12 lo llamaremos X”. Y en lugar de decir que “a la variable Y le asignamos la variable X”, lo correcto sería decir que “la variable X también se va a llamar Y”. Pero la costumbre pesa más que la corrección.
Pensando en un lenguaje de programación como Python, donde todo son objetos, podemos ver nuestro entorno como un gran ecosistema poblado de objetos de todo tipo, que se crean, interaccionan y se destruyen. Al principio de una aplicación, sólo contamos con acceso a unos pocos objetos y nos las tenemos que apañar para acceder al resto de objetos a través de operaciones y llamadas a los distintos módulos disponibles. Nuestro espacio de nombres inicial se irá expandiendo progresivamente con las referencias de los objetos de nuestro mundo conocido.
Ciclo de la vida de un objeto
Lo primero que hay que tener claro es que en python no tenemos verdadero control sobre la creación y destrucción de los objetos. Sólo podemos asegurar que un objeto existe mientras haya una referencia que lo enlace. Para saber qué pasa, tendremos que indagar en el funcionamiento del intérprete python.
Objetos básicos
x = 2 + 3
En esta expresión, el intérprete emplea dos objetos existentes, ‘2‘ y ‘3‘, y obtiene un tercer objeto, ‘5‘, al que asigna el nombre de ‘x‘. El objeto ‘5‘ no sabemos si lo ha creado en el momento de evaluar la expresión o si ya existía.
Como optimización del intérprete, siempre están creados un conjunto de los objetos más comunes. Estos objetos son los números enteros desde -5 a 256 (incluido el 0), los booleanos True y False, None y los conjuntos vacíos inmutables (), frozenset() y "".
Para saber si dos objetos son el mismo, podemos usar la función id. Podemos decir que dos objetos son el mismo si la función id devuelve el mismo valor. Así, podríamos obtener fácilmente la lista de los números enteros que siempre tiene creados el intérprete:
[i for i,j in zip(range(-100,1000),range(-100,1000)) if id(i) == id(j)]
Internalización de cadenas
Más curiosas resultan las “internalizaciones” de las cadenas de caracteres. Para acelerar las búsquedas, el intérprete mantiene una tabla global interna con las palabras usadas en nombres de variables, funciones, módulos, etc. Adicionalmente, toda cadena de caracteres que usemos que cumpla con las reglas sintácticas para ser nombres de variables acabarán automácamente dentro de esta tabla interna.
Además de este funcionamiento automático, podemos forzar a que una cadena entre en esta tabla con la función intern (sys.intern en python3).
Pues bien, todas las cadenas de caracteres de la tabla interna sólo son creadas una vez durante toda la ejecución del programa y permacerán ahí hasta el final.
>>> a="hola"
>>> b="hola"
>>> id(a)==id(b)
True
>>> a="hola mundo"
>>> b="hola mundo"
>>> id(a)==id(b)
False
>>> a=intern("hola mundo")
>>> b=intern("hola mundo")
>>> id(a)==id(b)
True
No siempre funciona el mecanismo de internalización y el intérprete crea una nueva cadena de caracteres:
>>> a="hola"
>>> c="HOLA".lower()
>>> id(a)==id(c)
False
>>> c=intern("HOLA".lower())
>>> id(a)==id(c)
True
Por culpa de la internalización nunca podremos estar seguros de cuándo se crea una cadena de caracteres. Más allá de este hecho, nunca nos debería preocupar el internalizar o no las cadenas de caracteres que usemos. Al menos, yo no he encontrado ninguna ventaja concreta de hacerlo.
Asignaciones
Ya hemos comentado que una asignación directa no crea un objeto nuevo, si no que enlaza una nueva etiqueta con el objeto existente:
x = y
En este caso, el mismo objeto al que apunta ‘y‘ también será al que apunte ‘x‘. Muchas veces no querremos que esto ocurra, sobre todo en el caso de listas. El truco consiste en convertir la asignación directa en una expresión que cree un nuevo objeto, pero de igual valor. Para ello usaremos las operaciones idempotentes para cada tipo de dato:
Para números en general, podemos usar los elementos neutros de las operaciones y*1 ó y+0:
>>> x=2.0
>>> y=x
>>> id(y)==id(x)
True
>>> y=x*1
>>> id(y)==id(x)
False
>>> y==x
True
En el caso de listas, por convenio se suele usar el operador split lista[:], pero podríamos usar cualquier otro como lista*1 o lista+[].
Destrucción de un objeto
Saber cuándo acaba la vida de un objeto suele ser la parte que más despista a quienes vienen a python desde otros lenguajes donde se acostumbra a hacer desaparecer un objeto por la fuerza.
Una vez más: en python, un objeto existe mientras esté referenciado.
Sólo cuando desaparezca la última referencia al objeto se llamará a su destructor (método __del__) y será eliminado de memoria.
No nos preocupamos de ello, pero cuando finaliza la ejecución de una función o de un método, desaparecen todas las referencias que habíamos creado. No hace falta que lo hagamos explícitamente. Todos los objetos creados durante la ejecución dejan de estar referenciados y serán destruidos, con excepción de aquellos que se retornen como resultado.
Pero hay veces que guardamos referencias a objetos que ya no nos hacen falta, y no somos muy conscientes de que por culpa de estas referencias estos objetos no son destruídos. Por ejemplo, es frecuente ver aplicaciones que mantienen una lista de ventanas abiertas. Por culpa de esta lista, las ventanas siempre estarán referencias. Si en el destructor estaba el código para eliminar la ventana y sus componentes, resulta que nunca será llamado. Hace falta eliminar la referencia de la lista de ventanas para que la ventana sea destruida finalmente.
En próximos artículos veremos técnicas mejores, como son usar “referencias débiles” (weakrefs). Las weakrefs vienen a ser referencias a objetos que no obligan a que el objeto esté siempre vivo. Si todas las referencias un objeto son weakrefs, entonces el objeto podrá ser destruído.
Referencias circulares
Algunas veces, los objetos mantienen referencias entre ellos conocidas por “referencias circulares”:
>>> a=[]
>>> b=[a]
>>> a.append(b)
>>> a
[[[...]]]
De querer eliminar ambos objetos, no podríamos hacer nada al estar referenciados mutuamente. Para estos casos, el intérprete de python tiene un proceso propio que se dedica a detectar estas referencias circulares llamado “Recolector de Basura”, más conocido por sus siglas GC (Garbage Collector). GC es un proceso que está permanentemente explorando la memoria para mantenerla limpia de objetos innecesarios, siendo parte vital para el correcto funcionamiento del intérprete. (Más información, en la documentación del módulo gc).